
【Netty】网络编程学习
该文章仅用作个人学习笔记!
参考文章:
选择器与 IO 多路复用
常见的 IO 多路复用模型,采用选择器的方案实现。当服务器与客户端存在某一状态(连接请求、读、写)时,才会进行处理,相比于传统的 IO(接收完客户端请求后,会阻塞等待读操作)

当有多个连接到服务器时,有下面的方式进行处理:
select:当这些连接出现具体的某个状态时,只是知道已经就绪了,但是不知道详具体是哪一个连接已经就绪,每次调用都进行线性遍历所有连接,时间复杂度为
O(n),并且存在最大连接数限制。poll:同上,但是由于底层采用链表,所以没有最大连接数限制。
epoll:采用事件通知方式,当某个连接就绪,能够直接进行精准通知(这是因为在内核实现中epoll是根据每个fd上面的callback函数实现的,只要就绪会会直接回调callback函数,实现精准通知,但是只有Linux支持这种方式),时间复杂度
O(1),Java在Linux环境下正是采用的这种模式进行实现的。
再 Java 中网络通信具体实现多路复用的代码如下:
1 | public static void main(String[] args) { |
NIO 框架存在的问题
客户端关闭导致服务端空轮询
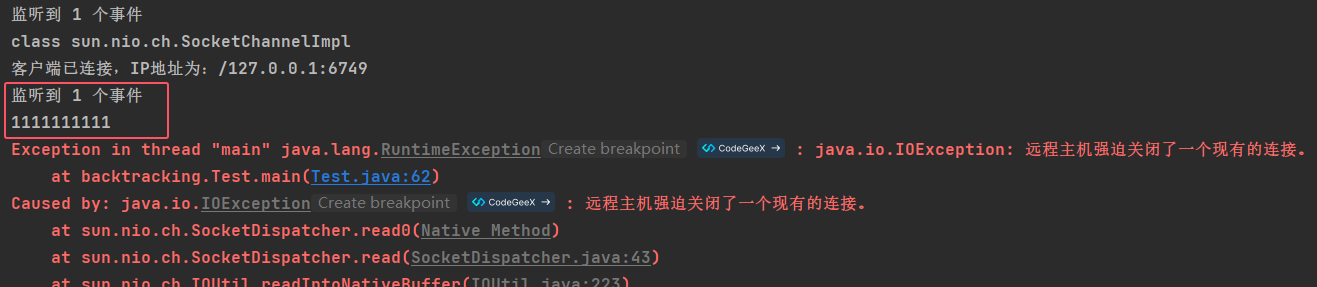
当客户端主动断开与服务端的连接时,服务端会进入一个莫名其妙的 READ 事件,直到 Java 抛出异常。这意味着,在客户端断开连接时,select 会直接允许其通过,从而触发后面的操作。
原因:
- 在 TCP 协议中,当客户端关闭连接时,会发送一个 FIN 包,通知服务端不再发送数据,但仍可以接收服务端发送的数据。
- 服务端的
SocketChannel会检测到这个 FIN 包,从而触发SelectionKey.OP_READ事件。此时,调用SocketChannel.read(ByteBuffer)会返回-1,表示客户端已关闭连接。
SocketChannel.read(ByteBuffer)返回读取到的字节数
这下明白了,原来是因为客户端返回了一个 -1,我们只需要进行额外的判断即可:
1 | if(channel.read(buffer) < 0) { |
框架本身问题
除上述客户端主动断开发送 FIN 包导致的问题外,Java NIO 框架本身还有问题导致空轮询。
即使没有任何通道准备好 I/O 操作,Selector.select() 方法仍然会返回,并陷入无意义的循环,从而导致 CPU 占用率异常升高
JDK 官方认为这是操作系统的 BUG:
- 在 Linux 2.6.32 及更早的版本中,
epoll可能会触发 “wake-up FD” 的问题。 - 特定条件下,
epoll的内部数据结构会被错误更新,导致select()方法误以为有事件发生。
TCP 半包和粘包问题
TCP 时面向流的,数据之间没有界限,且在发送数据前会将数据存放在缓冲区,具体什么时候发送由其自己控制。
半包
如果 TCP 一次传输的数据大小超过发送缓冲区的大小,那么一个完整的报文就被拆分了,可能会导致接收端收到不完整的数据。
粘包
如果 TCP 一次传输的数据大小小于发送缓冲区,那么可能回合别的报文合并起来一起发送,造成粘包
Netty 框架
Netty 是一个高性能、异步的事件驱动网络框架,基于 Java NIO(New IO)实现,用于构建高并发、低延迟的网络应用。它封装了复杂的底层 I/O 操作(如 Selector、多线程模型、协议解析),并提供了简单易用的 API,适合开发各种通信协议和应用。
ByteBuf 介绍
相比于原生的 NIO,Netty 使用 ByteBuf 作为缓冲区进行数据装载。
相比于原生 ByteBuffer,其不同之处在于:
- 写操作后无需进行
flip()翻转。 - 具有更快的响应速度
- 动态扩容

在内部其同时维护 读指针 和 写指针,这样就不需要 flip() 翻转了。
基本使用
1 | public static void main(String[] args) { |
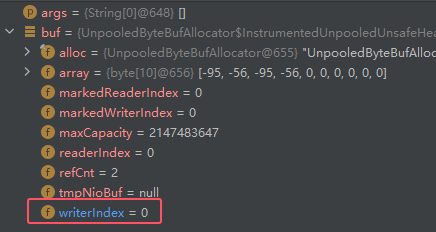
在进行一些涉及删除的操作时,其内部其实并没有修改具体的字节数据,而只是修改了操作指针的合法范围:
自动扩容
当我们写入一个超过容量的数据时,会进行自动扩容,第一次扩容会从 64 开始,之后每次扩容都会 x2,如果不希望其自动扩容,可以设置最大容量。
1 | public static void main(String[] args) { |
缓冲区的三种实现
实现模式:堆缓冲区模式、直接缓冲区模式、复合缓冲区模式。
前两者和 ByteBufer 一样,前者基于数组,后者基于直接内存,我们直接看第三个,复合模式,复合模式可以任意地拼凑组合其他缓冲区。
1 | //创建一个复合缓冲区 |
其本质是缓冲区的组合试图,并没有拷贝组合原先的缓冲区,而是将原先的两个缓冲区映射到一起操作。

池化和非池化
Unpooled 在内部通过 ByteBufAllocator 创建缓冲区,而 ByteBufAllocator 具备两个实现,UnpooledByteBufAllocator 和 PooledByteBufAllocator,一个是非池化缓冲区生成器,还有一个是池化缓冲区生成器。

实际上池化缓冲区利用了池化思想,将缓冲区通过设置内存池来进行内存块复用,这样就不用频繁地进行内存的申请,尤其是在使用堆外内存的时候,避免多次重复通过底层 malloc() 函数系统调用申请内存造成的性能损失。
比如下面的代码,两次创建的缓冲区是同一块内存。
1 | public static void main(String[] args) { |

零拷贝
零拷贝是一种 IO 优化操作,简单说就是避免在用户态和内核态之间拷贝数据的技术,从而减少 CPU 占用和内存带宽的消耗。
我们的应用程序实际上是运行在用户空间的,内核空间运行着系统层面的东西,比如我们在 Java 中创建一个新的线程,实际上最终还是要交给操作系统来为我们进行分配的。
IO 操作也是如此,需要操作系统帮我们从磁盘上读取文件数据或是向网络中发送数据,如下流程:

这就无可避免的要在内核空间和用户空间进行数据的拷贝,消耗资源。
而实现零拷贝有以下方案:
使用虚拟内存
将内核空间和用户空间的虚拟地址都指向同一个物理地址,就像于公用一块区域,也谈不上拷贝了:

ByteBuf 直接缓冲区
ByteBuf 提供了直接缓冲区和堆缓冲区两种类型。
直接缓冲区可以使用本地内存,正常情况下 JVM 需要数据从堆外拷贝到堆内才能访问,而直接缓冲区可以避免这个操作,减少数据拷贝。
内存映射文件
将内核空间的缓存映射到用户空间,这样就不需要从内核空间读取数据到用户空间了,数据处理完毕后,直接在内核空间将数据发送给缓冲区。

FileRegion 接口
FileRegion是 Netty 提供的用于文件传输的接口,通过调用操作系统的sendfile函数实现文件零拷贝传输。sendfile函数可以将文件数据直接从文件系统发送到网络接口,而无需经过用户态内存拷贝。
CompositeByteBuf
Netty 中的零拷贝其实还有另一层含义,即避免了 buffer 之间的拷贝。
CompositeByteBuf可以将两个 Buffer 逻辑上组成在一起,从而避免数据拷贝。1
2
3CompositeByteBuf buf = Unpooled.compositeBuffer();
buf.addComponent(Unpooled.copiedBuffer("abc".getBytes()));
buf.addComponent(Unpooled.copiedBuffer("def".getBytes()));
作者有点懒,笔记持续更新……





